
我们都了解HashMap,初始容量默认为16,源码上面说必须为2的幂,但是为什么容量总是为2的次幂呢。

为什么要保证 capacity 是2的次幂
在get方法中tab[(n-1)&hash]是计算key在tab中的索引位置,当key的hash没有冲突时,key在HashMap存储的位置就是匹配的node中的第一个节点。如果hash有冲突,就会在node里面节点中查询,直至匹配到相等的key。put方法同样如此,在put(key,value)的内部实现中:首先根据key得到hashcode,然后根据hashcode得到要存储的位置i=hash&(n-1),其中n为数组的长度。
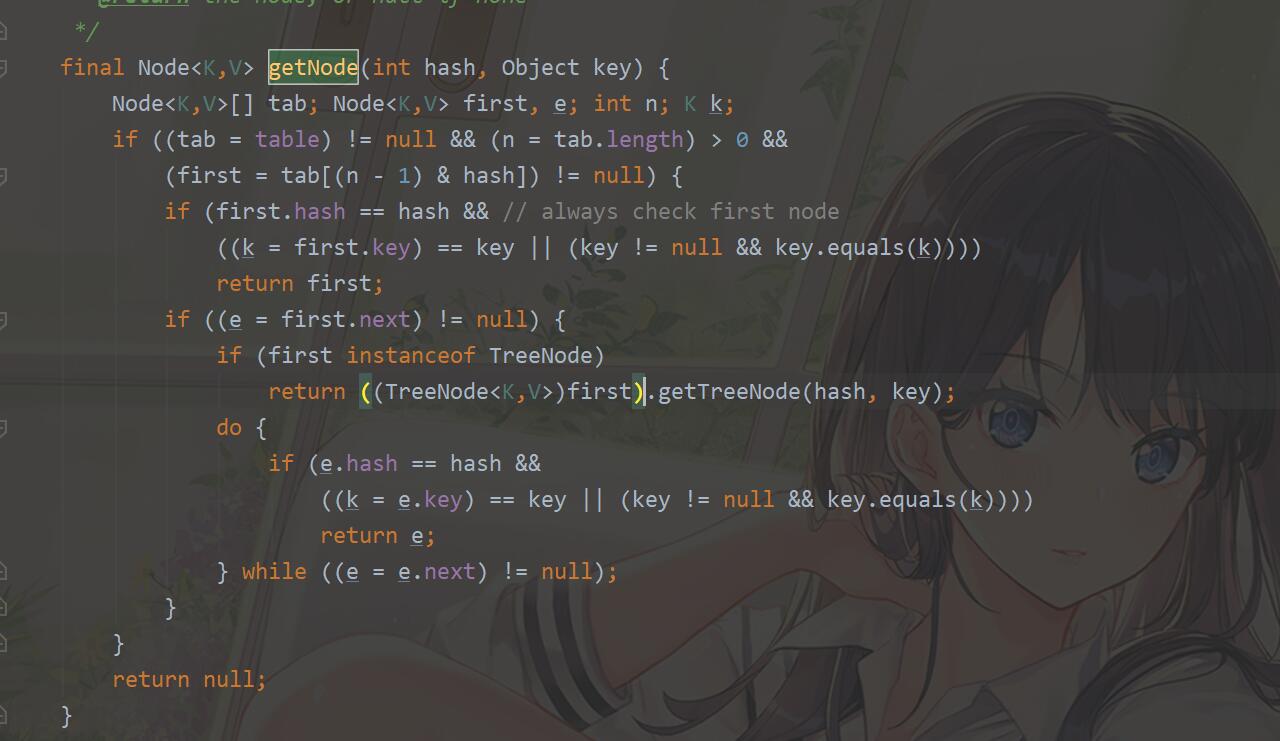
我们知道,在Java中位运算的速度比%取模的速度要快,如果n是2的幂,hash&(n-1)才能与hash%n等价
1 | 16的二进制为:0001 0000 |
为什么要通过 (n - 1) & hash 决定桶的索引
(1)key具体应该在哪个桶中,肯定要和key挂钩的,HashMap顾名思义就是通过hash算法高效的把存储的数据查询出来,所以HashMap的所有get 和 set 的操作都和hash相关。
(2)既然是通过hash的方式,那么不可避免的会出现hash冲突的场景。hash冲突就是指 2个key 通过hash算法得出的哈希值是相等的。hash冲突是不可避免的,所以如何尽量避免hash冲突,或者在hash冲突时如何高效定位到数据的真实存储位置就是HashMap中最核心的部分。
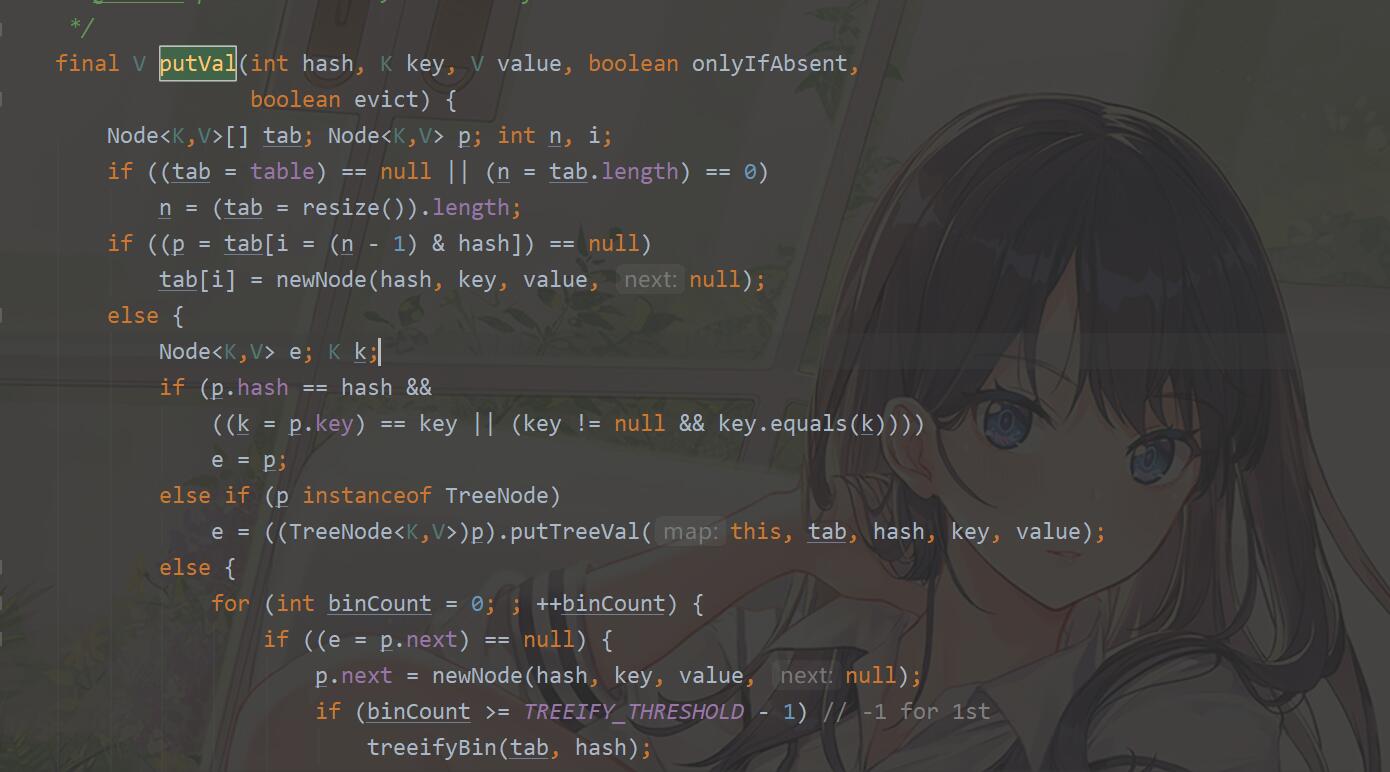
(3)首先要提的一点是 HashMap 中 capacity 可以在构造函数中指定,如果不指定默认是2 的 (n = 4) 次方,即16。
HashMap中的hash也做了比较特别的处理,(h = key.hashCode()) ^ (h >>> 16)。
先获得key的hashCode的值 h,然后 h 和 h右移16位 做异或运算。
实质上是把一个数的低16位与他的高16位做异或运算,因为在前面 (n - 1) & hash 的计算中,hash变量只有末x位会参与到运算。使高16位也参与到hash的运算能减少冲突。
例如1000000的二进制是 00000000 00001111 01000010 01000000
右移16位: 00000000 00000000 00000000 00001111
异或 00000000 00001111 01000010 01001111

如果我们令初始容量不为2的幂,是不是就破坏机制了
源码中HashMap的tableSizeFor方法做了处理,能保证n永远都是2次幂。

这个算法是返回大于输入参数且最近的2的整数次幂的数,比如10,返回16,详解如下
1 | |=是位或符号 |