B+树
B+树是一种树数据结构,通常用于数据库和操作系统的文件系统中。B+ 树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。B+ 树元素自底向上插入,这与二叉树恰好相反。在MySQL数据库中,诸多存储引擎使用的是B+树,即便其名字看上去是BTREE。
查找:
- 从根节点开始,如果查找的数据比根节点小,就去左子树找,否则去右子树
- 和子树的多个关键字进行比较,找到它所处的范围,然后去范围对应的子树中继续查找
- 以此循环,直到找到或者到叶子节点还没找到为止
特点:
- 关键字数和子树相同, B 树中,节点的关键字用于在查询时确定查询区间,因此关键字数比子树数少一;而在 B+ 树中,节点的关键字代表子树的最大值,因此关键字数等于子树数
- 非叶子节点仅用作索引,它的关键字和子节点有重复元素,除叶子节点外的所有节点的关键字,都在它的下一级子树中同样存在,最后所有数据都存储在叶子节点中。
- 叶子节点用指针连在一起,叶子节点包含了全部的数据,并且按顺序排列,B+ 树使用一个链表将它们排列起来,这样在查询时效率更快。B+ 树的查找必会查到叶子节点,更加稳定。
优点:
- 层级更低,IO 次数更少
- 每次都需要查询到叶子节点,查询性能稳定
- 叶子节点形成有序链表,范围查询方便
索引
分类:
主键索引:不能重复。id
单值索引:单列,age;一个表可以多个单指索引,name
唯一索引:不能重复。id
复合索引:多个列构成的索引(相当于二级目录: z :zhao)
创建索引:
方式一:
create 索引类型 索引名 on 表(字段)
单值:
create index dept_index on tb(dept);
唯一:
create unique index name_index on tb(name)
复合索引
create index dept_name_index on tb(dept,name)
方式二:alter table 表名 索引类型 索引名(字段)
单指:
alter table tb add index dept_index(dept)
唯一:
alter table tb add unique index name_index(name)
复合索引
alter table tb add index dept_name_index(dept,name)
注意:如果一个字段是primary key,则该字段默认就是 主键索引
删除索引
drop index 索引名 on 表名
drop index name_index on tb;
查询索引
show index form tb;
MySQL的SQL优化
原因:性能低、执行时间太长、等待时间太长、SQL语句欠佳(连接查询)、索引失效
a.SQL:
编写过程:
select dinstinct ..from ..join ..on ..where ..group by ..having ..order by
解析过程:
from .. on ..join ..where ..group by …having …select distinct ..order by
b.SQL优化,主要就是在优化索引
索引:相当于书的目录
索引:index是帮助MySQL高效获取数据的数据结构。索引是数据结构(树:B树(默认)hash树)
索引的弊端:
1.索引本身很大,可以存放在内存/硬盘(通常为硬盘)
2.索引不是所有情况均适用:a.少量数据 b.频繁更新的字段 c.很少使用的字段
3.缩影会降低增删改的效率
优点:1提高查询效率(降低IO使用率)
2降低CPU使用率
MySQL索引过程
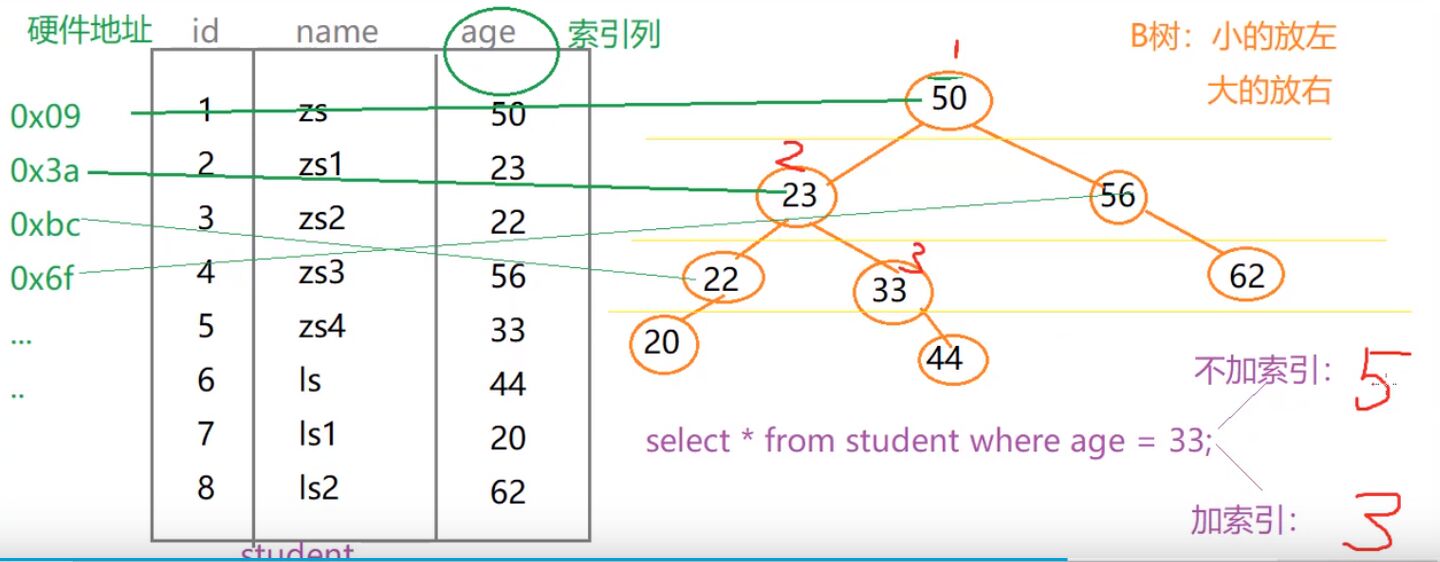
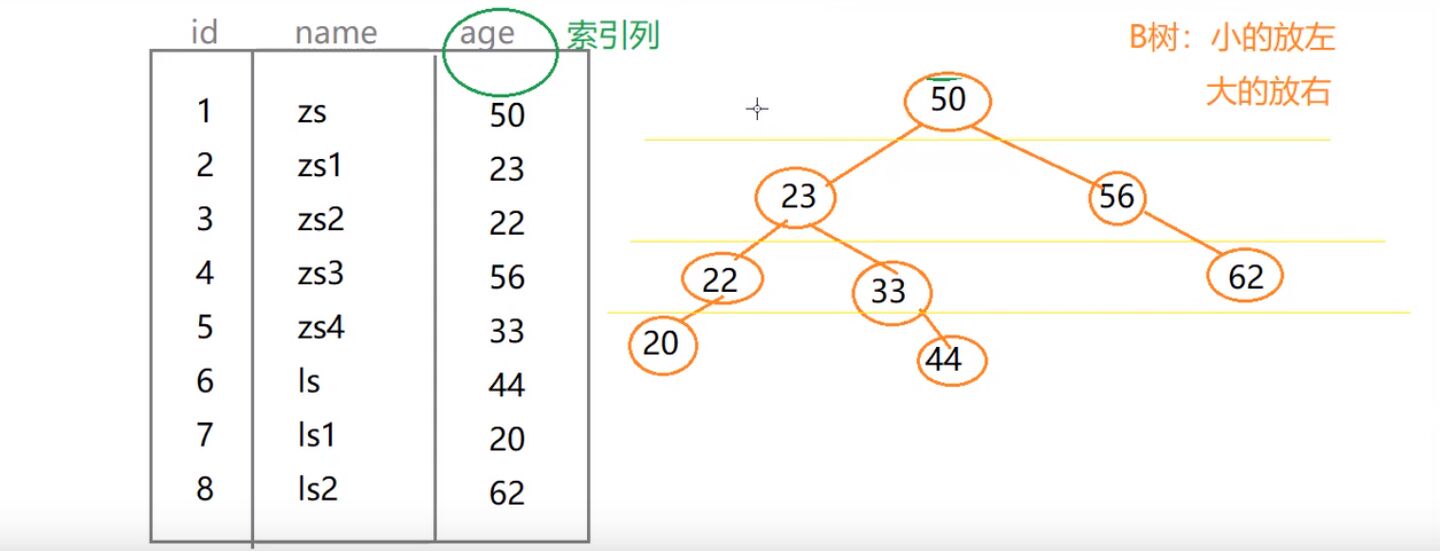
建立索引:如图,age为索引列,索引为B树的数据结构存在
索引与地址映射
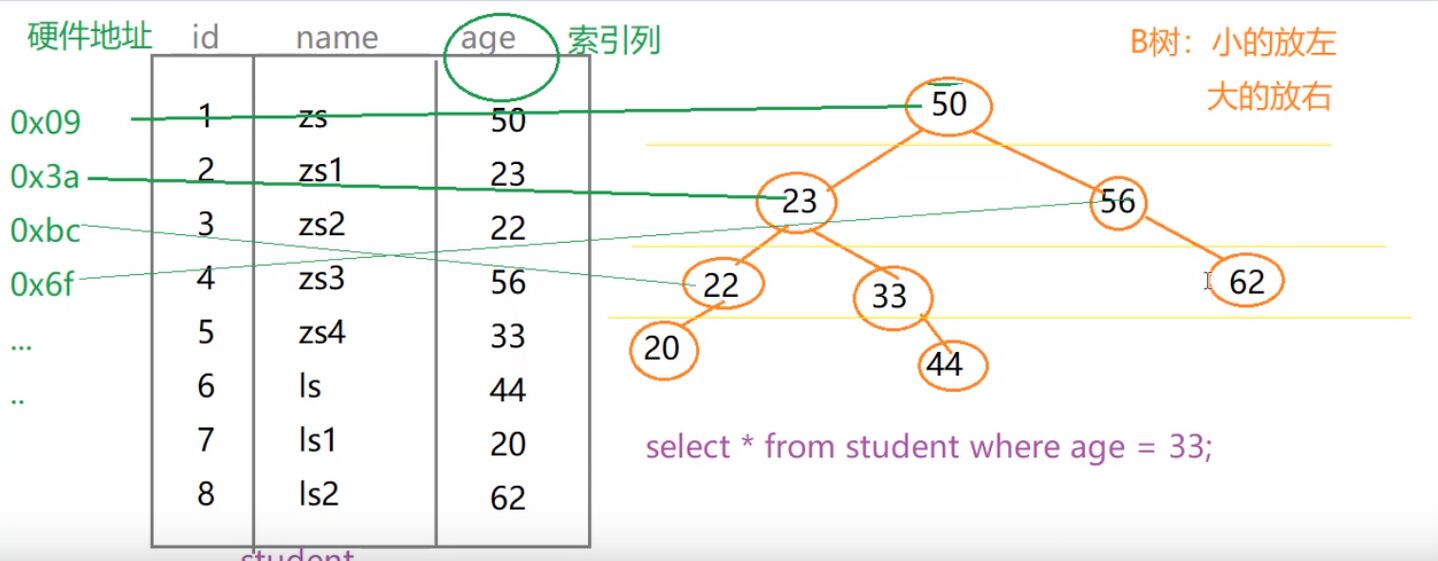
查找