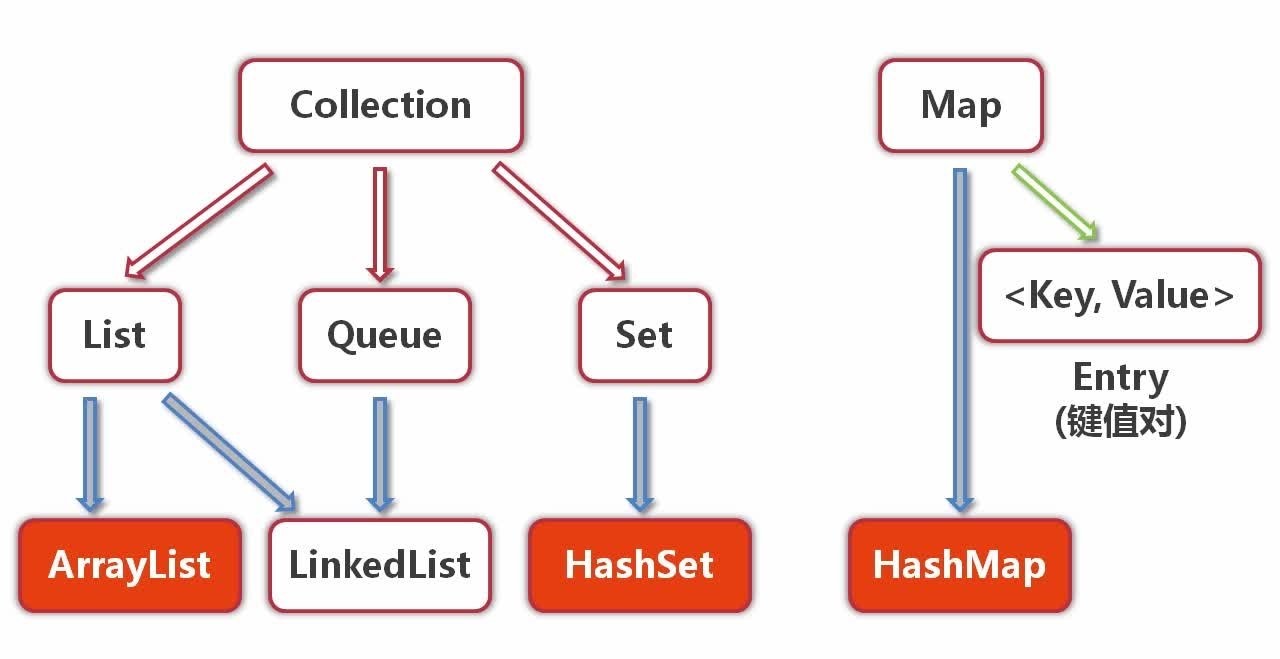
Java集合类详解(一 概括)
Java集合类主要有两大分支:
一、实现Collection接口
(一)List接口
1.ArrayList
ArrayList以数组实现。节约空间,但数组有容量限制。超出限制时会增加50%容量,用System.arraycopy()复制到新的数组,因此最好能给出数组大小的预估值。默认第一次插入元素时创建大小为10的数组。ArrayList是一个相对来说比较简单的数据结构,最重要的一点就是它的自动扩容,可以认为就是我们常说的“动态数组”。
2.LinkedList
LinkedList是一个双向循环链表,且头节点不存放数据,它也可以被当作堆栈,队列或双端队列进行操作,Linkedlist实现List接口,能对它进行队列操作,Header是双向链表的头节点,它是双向链表结点所对应的类Entry的实例。
3.Vector
Vector是矢量队列,它是Jdk1.0添加的类,实现了List,RandomAccess,Cloneable接口,继承了AbstractList,实现了List,所以它是一个队列,支持增删改查等功能。Vector实现了RandomAccess接口,所以提供随机访问功能,Vector实现了Cloneable接口,即实现了clone方法,可以被克隆。
(二)Set接口
1.TreeSet
TreeSet只能存放引用类型,不能用于基本数据类型,实现set接口,所以本身不能有重复的元素,当存入自定义的引用类型的时候就必须考虑到元素不可重复的这个特性,换句话说就必须实现Comparable接口(Comparable与Compared接口的区别),在TreeSet内部会自动调用存储的引用类型对象的实现的Comparable接口中的compareTo方法,如果不实现这个接口就会报错,因为找不到那个方法。自定义引用类型类由自己定义,实现的接口的方法由自己实现,这也就吧具体的比较对象交给了我们自己,在用TreeSet存放元素的时候的排序规则由自己定义。
2.HashSet
HashSet简单的理解就是HashSet对象不能存放相同的数据,存放数据时是无序的,但是HashSet存储元素的顺序并部署按照存入时的顺序,是按照哈希值来存也是按照哈希值来取得,
3.LinkedHashSet
LinkedHashSet是Set集合的一个实现,具有set集合不重复的特点,同时具有可预测的迭代顺序,也就是我们插入的顺序,并且linkedHashSet是一个非线程安全的集合。如果有多个线程同时访问当前linkedhashset集合容器,并且有一个线程对当前容器中的元素做了修改,那么必须要在外部实现同步保证数据的冥等性
二、实现Map接口
(一)AbstractMap
1.HashMap
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。此外,HashMap中的映射不是有序的。
2.TreeMap
TreeMap 是一个有序的key-value集合,它是通过红黑树实现的。TreeMap 继承于AbstractMap,所以它是一个Map,即一个key-value集合,TreeMap实现Cloneable接口,意味它能被克隆,实现了java.io.Serializable接口,意味着它支持序列化。
3.LinkedHashMap
LinkedHashMap通过维护一个运行于所有条目的双向链表,LinkedHashMap保证了元素迭代的顺序,该迭代顺序可以是插入顺序或是访问顺序。
(二)ConcurrentMap
1.ConcurrentHashMap
底层采用分段数组和链表实现,线程安全
(三)HashTable
底层数组和链表,无论key还是value都不能为null,线程安全,实现线程安全的方式是修改数据时锁住整个HashTable,效率低。